Reinforcement Learning
REINFORCEMENT LEARNING
Reinforcement learning (RL) is an area of machine learning concerned with how software agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.

without some feedback about what is good and what is bad, the agent will have no grounds for deciding which move to make.
The agent needs to know that something good has happened when it (accidentally) checkmates the opponent, and that something bad has happened when it is checkmated-or vice versa, if the game is suicide chess. This kind of feedback is called a reinforcement or reward.
Rewards served to define optimal policies in Markov decision processes (MDPs). An optimal policy is a policy that maximizes the expected total reward. The task of reinforcement learning is to use observed rewards to learn an optimal (or nearly optimal) policy for the environment. the agent has a complete model of the environment and knows the reward function.
- The agent does not know how the environment works or what its actions do, and we will allow for probabilistic action outcomes. Thus, the agent faces an unknown Markov decision process. We will consider three of the agent designs:
- A Q-learning agent learns an action-utility function, or Q-function, giving the ex Q-FUNCTION pected utility of taking a given action in a given state.
- A utility-based agent learns a utility function on states and uses it to select actions that maximize the expected outcome utility.
- A reflex agent learns a policy that maps directly from states to actions.
The principal issue is exploration: an agent must experience as much as
possible of its environment in order to learn how to behave in it.how
an agent can use inductive learning to learn much faster from its experiences.
The final approach we will consider for reinforcement learning problems is called policy search. In some ways, policy search is the simplest of all the methods: the idea is to keep twiddling the policy as long as its performance improves, then stop.
For example, we could represent π by a collection of parameterized Q-functions,
one for each action, and take the action with the highest predicted value:
π(s) = maxa Qˆθ(s, a).
or
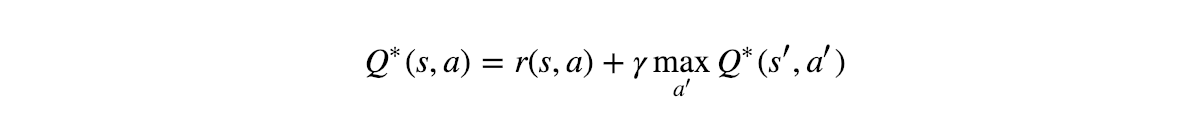
Each Q-function could be a linear function of the parameters θ,,
or it could be a nonlinear function such as a neural network. Policy search will then adjust the parameters θ to improve the policy. Notice that if the policy is represented by Q functions, then policy search results in a process that learns Q-functions. This process is
not the same as Q-learning!
reference:- Artificial intelligence a modern approach



Comments
Post a Comment